In a world dominated by multi-thread desires, and often single-thread limitations, hardware advancements can make the biggest difference in performance. AMD has released a new extension for x86 hoping to address at least part of that. Dubbed SSE5, this newest generation adds power to the x86 by introducing not only a whole new instruction class, but also powerful multiply-accumulate instructions as well. Both of these advancements should deliver notable savings in compute time.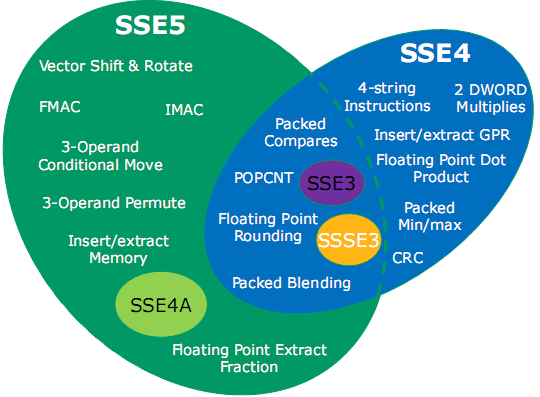
While extending the x86 instruction set with new iterations of SSE has become a regular activity in the computing industry, many of these additions are in actuality a gradual reshaping of x86 processors. Although as a general purpose CPU design x86 doesn't have any hard limitations (given enough time you can do any kind of calculation required) it has had several weak points patched up over the years. The basis of identifying and patching these weak points has been looking at what processors - general and specialized - are doing well while x86 is doing poorly at the time. Each iteration of SSE so far has then implemented features that these other processors have to erase these weak points.
All told, SSE5 includes 46 unique "base" instructions, with many of those instructions featuring several variations that work on different data types. With all of these variations, the total number of instructions introduced altogether with SSE5 is 170. For comparison's sake, the entire original x86 instruction set was a mere 80 instructions.
With SSE5, AMD is focusing on 5 groups of instructions. Those groups are:
* Fused multiply accumulate (FMACxx) instructions
* Integer multiply accumulate (IMAC, IMADC) instructions
* Permutation and conditional move instructions
* Vector compare and test instructions
* Precision control, rounding, and conversion instructions
As we hinted to earlier, many of these instructions are implementations of features found elsewhere. DSPs in particular have been and continue to be a major source of new instructions for new versions of SSE, with many of these instructions allowing for a CPU to process data for specialized cases at DSP-like speeds.
AMD has provided us with an example of such a situation, with the code for a 4x4 matrix multiplication operation, one coded optimally in SSE3, the other optimized via SSE5. The SSE3 code requires 34 instructions, meanwhile the SSE5 code does it in 20. Now there is more to the performance of such a code segment than the number of instructions (so this example isn't necessarily 41% faster) since the time to execute and retire an instruction can vary depending on the instruction, but it doesn't negate the performance improvement offered by such code.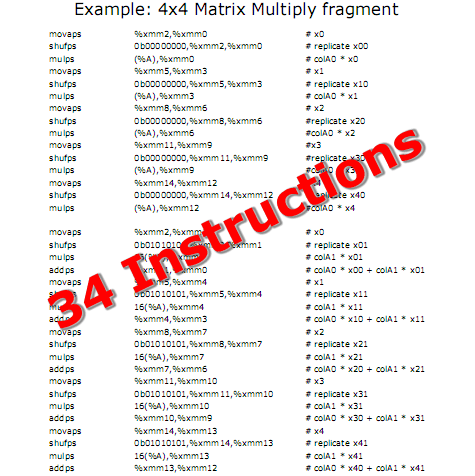

For actual performance numbers with SSE5, AMD has told us that they've found that a discrete cosine transform - an operation important for image and movie encoding - can be done 30% faster using SSE5 than SSE3. They have even more impressive numbers for encryption processing, with a 5x performance improvement possible on certain encryption tasks, although we suspect this case is more limited than their image encoding scenario. Either way the promise of other performance improvements is there, however this is going to heavily depend on how well programmers will be able to extract additional performance out of SSE5, and how good AMD's own optimized math libraries will be once those are released.
SSE5 philosophy
Both AMD and Intel are looking primarily at future software needs when they consider which way to move with hardware advancements. The recognition that future software will benefit from parallel operations is an absolutely paramount realization. AMD is looking at compute-intensive, multi-media and security applications with SSE5. It is are targeting a wide industry adoption through many software vendors. And full tool support is expected to be available in 2008, including a fully-supported GCC compiler.
Conclusion
SSE5 extends performance boundaries with new, combined and three-operand instructions. AMD's efforts in the x86 arena reveal a very clear focus and intent. AMD is looking at the needs of the software industry and bringing forth hardware which addresses many of those needs. AMD's Light-Weight Profiling (LWP) initiative is another example which provides, via hardware, useful tools. LWP provides a way for software developers to know things they might not otherwise be able to know, and certainly without custom-developed, complex and costly runtime analysis add-ons.
Sumber :
http://anandtech.com
http://www.tgdaily.com
Friday, August 31, 2007
A New SSE Instruction Set: AMD Announces SSE5
Diposting oleh Aan #3 di 3:05 PM
Label: Artikel Komputer
Subscribe to:
Post Comments (Atom)

0 komentar:
Post a Comment